概述
正则表达式是一种用于匹配字符串模式的强大工具。它们在文本处理、数据验证和各种其他应用程序中广泛使用。正则表达式语法是一个由特殊字符和元字符组成的体系, 用于定义要匹配的模式。
基本语法
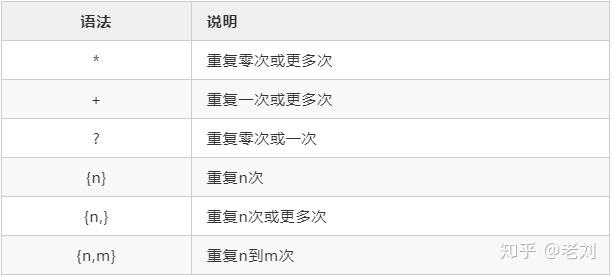
字符类方括号 ([]):匹配方括号内指定的任何字符。例如,`[abc]` 匹配字符 “a”、”b” 或 “c”。连字符 (-):表示字符范围。例如,`[a-z]` 匹配所有小写字母。脱字符 (\):转义字符的特殊含义。例如,`\[` 匹配 “[“字符本身。量词星号 ():匹配前一个元素零次或多次。例如,`a` 匹配零个或多个 “a” 字符。加号 (+):匹配前一个元素一次或多次。例如,`a+` 匹配一个或多个 “a” 字符。问号 (?):匹配前一个元素零次或一次。例如,`a?` 匹配零个或一个 “a” 字符。分组圆括号 (()):将表达式分组。例如,`(ab)+` 匹配一个或多个 “ab” 子字符串。限定符花括号 ({}):指定匹配次数。例如,`a{2}` 匹配两个 “a” 字符。管线 (|):表示可选元素。例如,`a|b` 匹配 “a” 或 “b”。
高级语法
边界锚点脱字符开头 (^):匹配字符串开头。脱字符结尾 ($) :匹配字符串结尾。单词边界 (\b):匹配单词边界。反向引用反斜杠反向引用 (\number):引用先前匹配的子表达式。例如,`\1` 引用第一个子表达式的匹配结果。贪婪和非贪婪量词贪婪量词:尽可能多地匹配字符。例如,`.` 匹配字符串中的所有字符。非贪婪量词:尽可能少地匹配字符。例如,`.?` 匹配字符串中尽可能少字符。
示例
下表列出了几个示例正则表达式及其匹配的字符串:| 正则表达式 | 匹配的字符串 |
|—|—|
| `^[a-z]+$` | 以小写字母开头和结尾的字符串 |
| `\d{3}-\d{4}` | 由一个三位数字和一个四位数字组成的字符串 |
| `.[aeiou].` | 包含至少一个元音字母的字符串 |
| `(a|b)+\.txt` | 以 “a.txt” 或 “b.txt” 结尾的文件名 |
结论
正则表达式语法是一个强大且多功能的工具,用于匹配字符串模式。通过了解基本和高级语法,您可以创建复杂的表达式来执行各种文本处理任务。
资源
[正则表达式教程](https://www.regular-expressions.info/)[正则表达式指南](https://www.regextester.com/943)
好看的电影推荐
© 版权声明
文章版权归作者所有,未经允许请勿转载。