混淆矩阵:理解机器学习模型中不同分类的性能概述混淆矩阵是一种表格,用于可视化和评估机器学习分类模型的性能。它提供有关模型对不同类别的预测如何与实际类别相匹配的深入见解。通过分析混淆矩阵,我们可以识别模型的优势和劣势,并采取措施进行改进。混淆矩阵的结构混淆矩阵是一个二维表格,其中行表示实际类别,而列表示预测类别。每个单元格的值表示属于真实类别的实例被预测为属于预测类别的数量。一个示例混淆矩阵如下:| 实际类别 | 预测为类别 A | 预测为类别 B |
|—|—|—|
| 类别 A | 80 | 20 |
| 类别 B | 15 | 85 |混淆矩阵中的术语真阳性 (TP):实际属于并被预测属于同一类别的实例数量。真阴性 (TN):实际不属于并被预测不属于同一类别的实例数量。假阳性 (FP):实际不属于但被预测属于某一类别的实例数量。假阴性 (FN):实际属于但被预测不属于某一类别的实例数量。混淆矩阵的度量指标混淆矩阵可用于计算以下度量指标:准确率:正确预测的所有实例的比例。精度:预测为特定类别的实例中实际属于该类别的实例的比例。召回率:实际属于特定类别的实例中被正确预测的实例的比例。F1 分数:精度和召回率的加权平均值。这些度量指标有助于量化模型对不同类别的预测能力。混淆矩阵的解读通过分析混淆矩阵,我们可以了解以下信息:模型的整体准确率:对角线单元格的值总和除以整个矩阵中的值总和。每个类别的精度和召回率:相应行和列中的值除以该行或列的总和。模型混淆的类别:具有高 FP 和 FN 值的类别。模型预测错误的方向:例如,如果 FP 值较高,则模型可能倾向于错误地将其他类别预测为特定类别。混淆矩阵的应用混淆矩阵用于各种机器学习应用中,包括:模型评估:评估模型对不同类别的性能并确定需要改进的领域。类不平衡处理:识别和解决小众类别的预测问题,这些类别的实例数量很少。超参数优化:调整模型超参数以最大化混淆矩阵中的对角线值。特征选择:识别对模型预测有重大贡献的特征,这些特征可以根据混淆矩阵中的值进行排名。结论混淆矩阵是评估机器学习分类模型性能的强大工具。通过分析混淆矩阵,我们可以深入了解模型对不同类别的预测能力,识别弱点并采取措施进行改进。混淆矩阵对于确保模型准确性和可靠性至关重要,尤其是在涉及多类的问题中。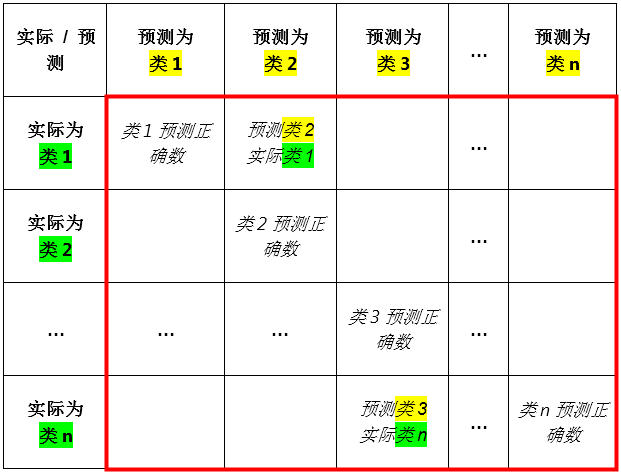
chat人工智能免费入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。








