Socket 通信是一种计算机之间的网络通信方式。在 Socket 通信中,如果涉及到中文数据的传输,则可能会出现中文乱码的问题。本文将提供一个综合指南,帮助您彻底解决 Socket 通信中中文乱码的问题。
中文乱码产生的原因
中文乱码产生的原因主要是由于数据在编码和解码过程中出现了问题。编码是指将中文数据转换为计算机可以识别的数字形式,解码是指将数字形式的中文数据还原成可读的中文。如果编码和解码过程中使用的字符集不一致,则就会产生中文乱码。
解决中文乱码的步骤
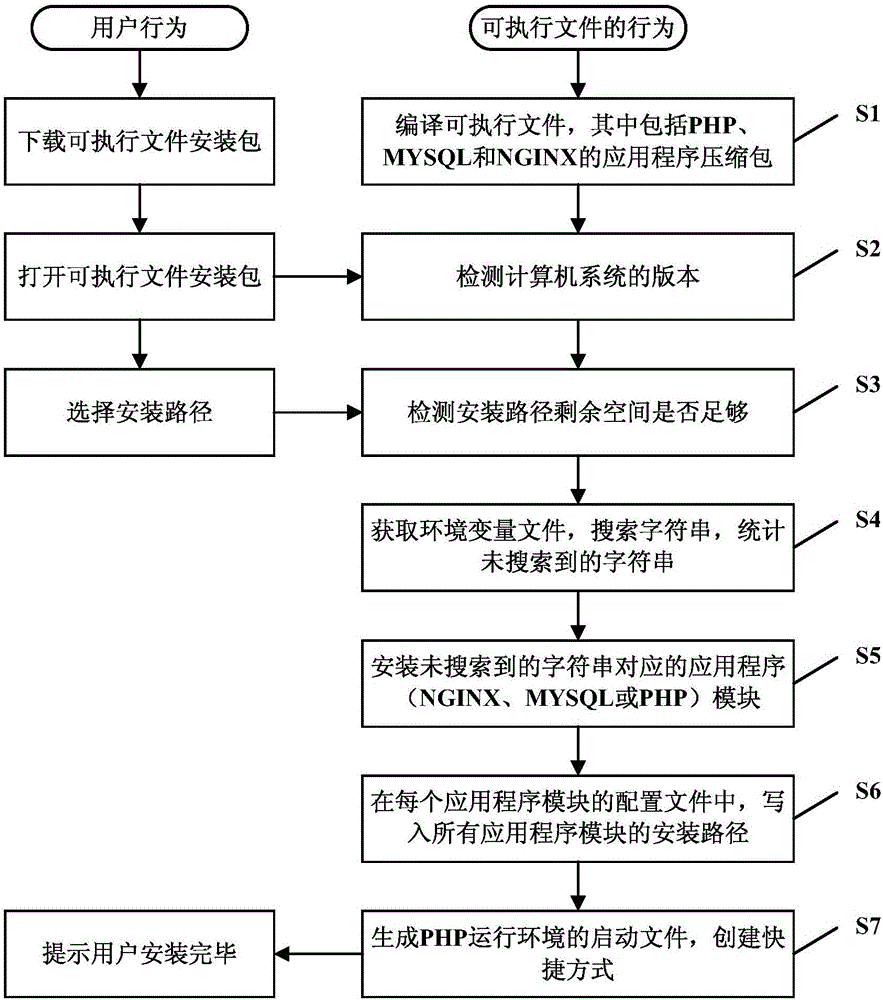
解决 Socket 通信中中文乱码的问题需要以下步骤:
1.确定使用的字符集
需要确定 Socket 通信中使用的字符集。常用的字符集包括 UTF-8、GBK、GB2312 等。您可以通过查看通信协议文档或与另一方沟通来确定使用的字符集。
2. 设置字符集
确定字符集后,需要在发送和接收数据的代码中设置字符集。在 Python 中,可以使用
encode()
和
decode()
方法来设置字符集,例如:
发送数据data = data.encode("utf-8")接收数据data = data.decode("utf-8")
3. 处理字节序
在某些情况下,还需要处理字节序。字节序是指将多字节字符存储在计算机中的顺序。不同的计算机系统使用不同的字节序,因此在 Socket 通信中需要确保发送和接收数据的字节序一致。在 Python 中,可以使用
struct
模块来处理字节序,例如:
将整数转换为大端字节序data = struct.pack(">i", 12345)
4. 使用流编码器
如果 Socket 通信涉及到大量的中文数据,则可以使用流编码器来提升性能。流编码器可以将中文数据分块编码和解码,从而避免对整个数据集进行编码和解码。在 Python 中,可以使用
codecs
模块中的流编码器,例如:
import codecs创建流编码器encoder = codecs.getencoder("utf-8")编码数据encoded_data = encoder(data)
5. 其他注意事项
除了上述步骤之外,还需要注意以下事项:
- 确保发送和接收数据的代码使用相同的字符集和字节序。
- 使用调试工具来检查编码和解码过程是否有问题。
- 如果仍然存在中文乱码,可以尝试使用不同的字符集或字节序。
总结
通过遵循本文中的步骤,您可以彻底解决 Socket 通信中中文乱码的问题。需要注意的是,不同的编程语言和操作系统可能需要使用不同的方法来处理中文乱码。如果您遇到任何问题,可以参考相关文档或寻求专业帮助。
© 版权声明
文章版权归作者所有,未经允许请勿转载。